



大部分企业部署AI Agent写代码,效果曲线是确定的:第一周惊艳,第一个月衰减,第三个月回归基线。
不是模型退步了。是上下文断了。
当前AI Agent落地最大的障碍不是模型能力。从OpenAI的GPT-5.5系列到Anthropic的Claude Opus 4.8,从Google的Gemini 3.5到阿里的Qwen3.7-Max——模型层的差距在缩小,编码能力已不是瓶颈。真正卡住企业的是另一个问题:Agent无法跨会话保持对项目、代码规范、历史决策的理解。每次新会话,它从零开始。上次的决策、上周的修改、上个月的架构讨论——全部丢失。
CORE PROBLEM
这不是体验问题。是架构缺陷。
01 CHAPTER ONE · SESSION LEVEL
会话级失忆:
每次对话,从零开始
最常见的断裂发生在会话边界。
上周四,你让Agent把支付模块的异常处理重构了一遍。它理解了你们为什么不直接用Spring的全局异常拦截器、为什么要把错误码映射写在业务层而不是网关层。重构质量不差,几处细节甚至让你有点惊喜。周五打开新会话继续。Agent问:支付模块的异常处理是怎么设计的?
KEY INSIGHT
这不是"忘了"。这是系统没有持久化机制。
现在市面上的Agent怎么记东西?把对话历史往prompt里塞。窗口塞满了,最早的消息,不管多重要都会直接丢掉。没有优先级,没有判断,纯物理淘汰。昨天的架构讨论和三天前的闲聊享受同等待遇:窗口装不下了,一起扔掉。
这带来一个反直觉的结果:单次会话里Agent确实让你变快了,但会话之间的重复补课把你的时间吃了回去。你今天教会它的东西,换个人用——重来。你自己下周接着用——重来。更糟的是,Agent输出的代码因为缺了一段上下文跑不通,你花了20分钟排查,最后发现逻辑没错,是它不知道你们上个月改过接口签名。
CONCLUSION
会话级失忆是表层的。但足以让Agent从"协作者"退化回"问答机"。
02 CHAPTER TWO · PROJECT LEVEL
项目级失忆:
换个人,换了个Agent
更深层的断裂发生在项目维度。
一个中等规模项目,十万行代码。Agent要跟上你的节奏,至少得知道这些:目录结构、模块边界、依赖关系、命名约定、异常处理策略、日志规范、测试覆盖要求。这些知识散落在代码里、commit message里、技术方案评审的聊天记录里。
一个开发者用Agent磨合了几周,Agent终于在这个人的会话里"清楚"了项目规范——哪些包禁止引入,异常怎么分类,接口版本怎么管理,log敏感信息怎么脱敏。这时候换一个同事,同一个项目,同一个Agent——归零。
CRITICAL
知识产生了,用完了,扔掉了。
更严重的是决策遗忘。项目演进过程中,技术选型、架构调整、接口设计,每一次决策都有其上下文和理由。Agent参与了决策,但没有能力保留决策依据。三个月后,新的需求触发了旧的决策边界,Agent无法回溯"为什么当时这样做"——它会提出与既有架构冲突的方案。开发者需要花时间解释为什么这个方案不可行。这个循环反复出现。
项目级失忆的直接后果
Agent的输出质量随代码库复杂度递减。简单项目好用,复杂项目越用越累。
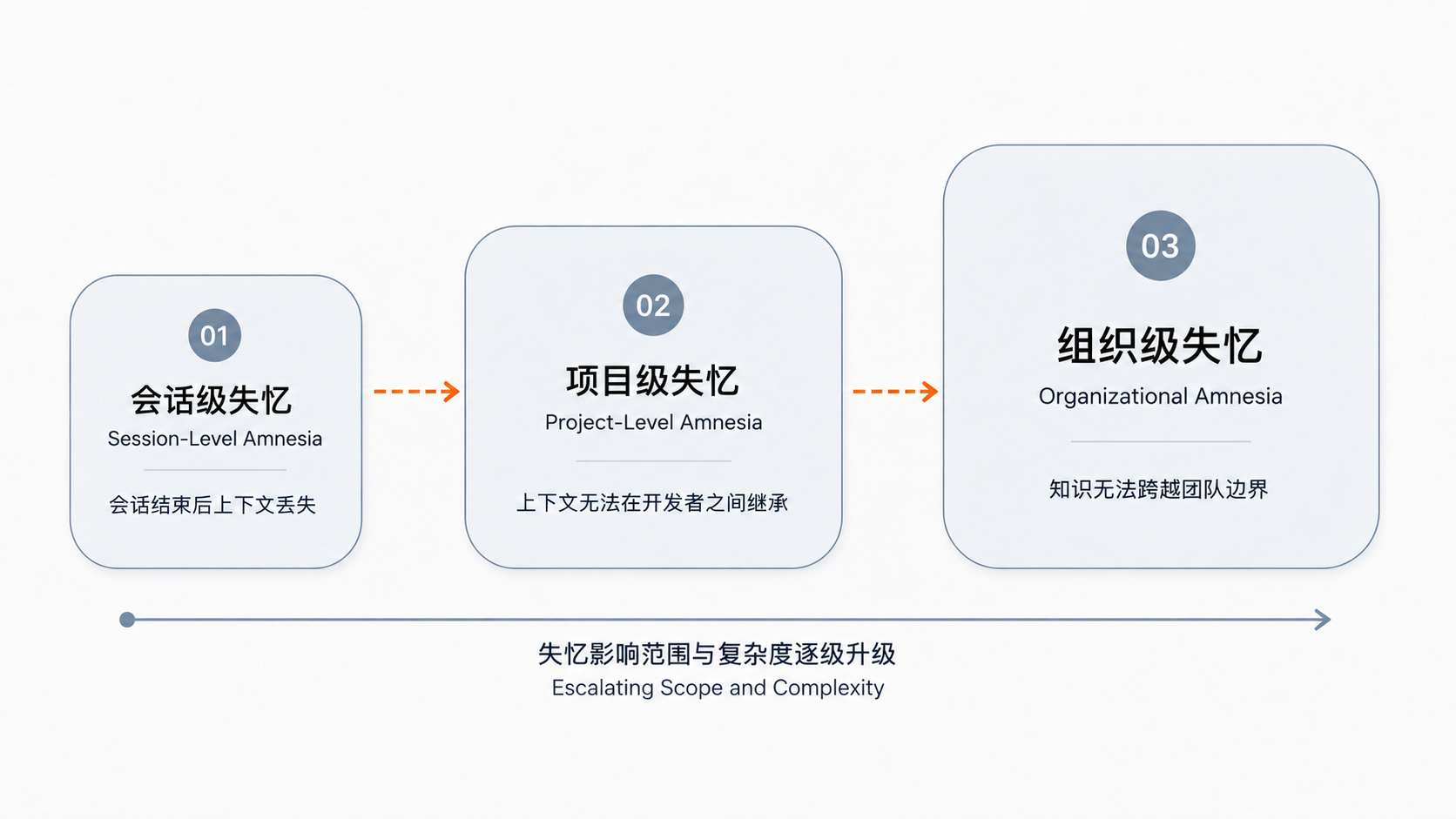
Fig.1 三级失忆模型:会话级 · 项目级 · 组织级
03 CHAPTER THREE · ORGANIZATION LEVEL
组织级失忆:
知识无法跨越团队边界
最隐蔽的断裂在组织层。
团队A花了两个月趟出来的最佳实践——组件怎么拆、性能怎么优化、CI/CD管线怎么配——团队B的Agent不知道。同一个公司,两套完全独立的"Agent经验"。不是不想共享,是压根没有共享的通道。
让Agent理解组织维度的约束更是无从谈起。它不知道公司禁止引入哪些三方库,不知道金融模块的数据脱敏规则是什么,不知道内网服务之间调用的鉴权协议。一个新人入职还有入职文档、还有老员工带着,Agent什么都没有。你只能自己在prompt里手动注入——"注意,公司不用gRPC""日志里不能打印用户手机号""这个接口要走内部网关鉴权"。
每次新项目启动,Agent对组织知识一无所知。靠开发者在prompt里手动注入规范?这不是规模化使用的方式。
SUMMARY
三级失忆叠加,Agent在企业里的真实效率曲线是:单次会话高效,跨会话衰减,跨项目归零。
REDEFINE · ARCHITECTURE
记忆不是缓存,是架构
这个定义决定了它的工程实现方式:它必须是一个独立的状态管理层,有自己的存储模型、读写接口、生命周期管理。它不是prompt工程,不是RAG的简单套用,不是向量数据库加一个检索接口。
一个合格的持久状态层,需要满足三个条件:

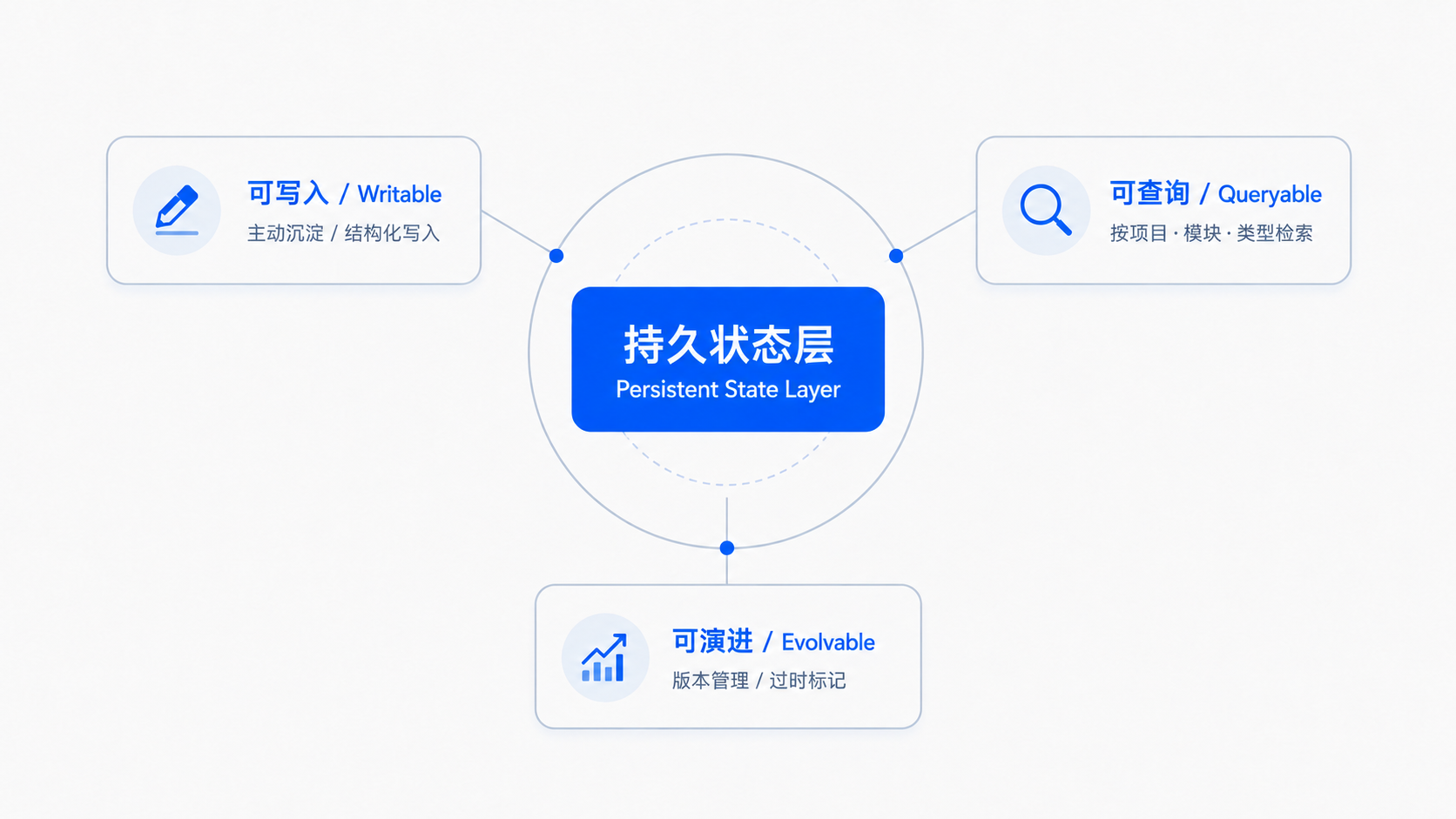
Fig.2 持久状态层三要素:写入 · 查询 · 演进
三个条件缺一不可
缺写入,知识无法沉淀;缺查询,知识无法复用;缺演进,知识无法迭代。
上下文持久化:
织灵的企业级记忆架构
基于上述定义,织灵实现了企业级上下文记忆。核心设计如下。
织灵的ADE数字机器人在工作过程中,自动将代码规范、架构决策、接口约定等上下文结构化写入企业记忆。不是原始对话日志的堆存,是经过提取和结构化的知识——按项目、模块、决策类型组织。写入时机嵌在工作流的自然节点上:代码提交、方案评审、规范确认。开发者不需要额外操作。
新会话启动时,ADE自动加载项目上下文。不是把所有历史塞进prompt,是按当前任务的相关性,精确注入必要的上下文。会话结束后,本轮产生的新上下文写回状态层。上下文在会话间持续积累,而非每次重建。
企业记忆支持项目级和团队级两个粒度。项目级记忆在同一项目的所有开发者间共享——A建立的规范,B的ADE直接使用。团队级记忆将最佳实践、安全策略、合规要求沉淀为组织资产,新项目自动继承。
访问权限与涉密分级对齐
记忆的访问权限与企业的涉密分级对齐。不是所有上下文对所有人可见,是按密级、按项目、按角色精确管控。金融模块的脱敏规则不会泄露到前端团队,核心算法的实现细节不会出现在外包项目的上下文中。
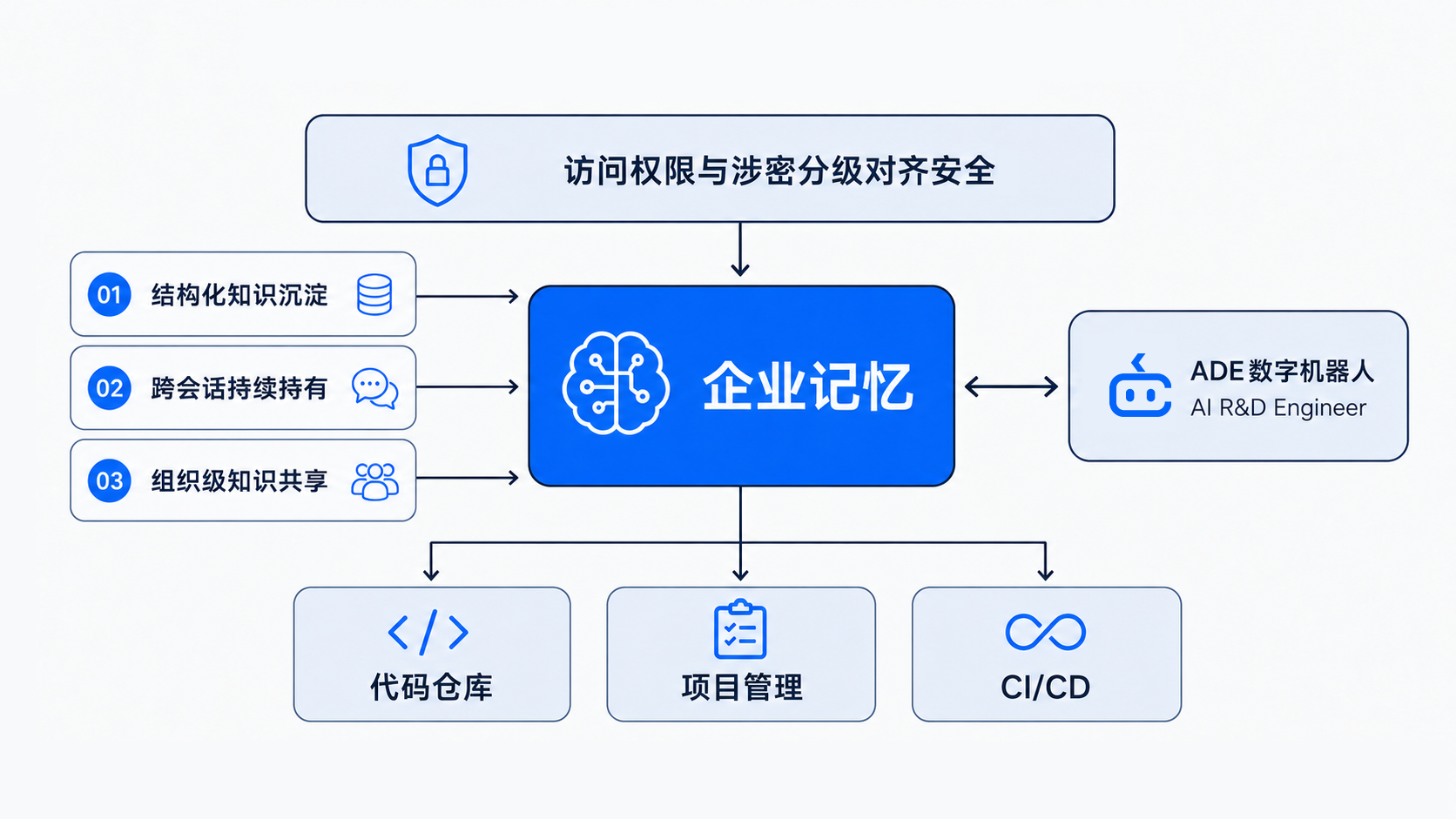
Fig.3 织灵企业记忆集成架构:跨系统状态层
织灵的记忆架构与企业现有研发系统——代码仓库、项目管理、CI/CD——深度集成。上下文的来源不局限于Agent自身的工作记录,还包括外部系统的变更事件。记忆不是Agent的私有状态,是整个研发环境的共享状态层。
没有记忆的Agent
只是按次计费的 API调用。
有记忆的Agent
才是协作者。