



KEY INSIGHT
方法论有两种来源。
一种是在白板上画出来的。架构图漂亮,原则清晰,每一条都说得通。唯一的缺陷是——它没有被任何人真正用过。
另一种是撞了很多次墙之后,在复盘记录里翻出来的。
我们属于第二种。
◆ 第一部分
V1.0:一个看起来完全成立的理论框架
最开始,我们有五条原则。
SDD · 规格驱动开发。动代码前先写好需求规格和验收标准,让Agent知道它要去哪。
SKILL · Agent能力封装。像给一个天赋极高的新人写操作手册。
TDD · 测试先于实现。Agent写代码快,但目标是快且对。
PDCA · Plan、Do、Check、Act。每个迭代不只是做完,而是做完、检查、改进。
执行状态管理 · 追踪文件。每个迭代发生了什么、什么做完了、什么欠着。
当时我们觉得——这五条,逻辑自洽,应该够了。
V1.0 交出的答卷
2个示例Skill · 1个迭代的演示 · 3个模板文件
没有测试数据 · 没有部署经验 · 没有实践文档
这是一个"正确但未经证实的答案"。
就像一份写得很好的菜谱。食材用量精确、步骤描述清晰、成品图诱人。但你还没有真正进过厨房。
▼ ▼ ▼
然后我们进了厨房
14个迭代。企业知识库系统。从需求分析到部署上线——

方法论不是一次设计完就定型了。它是在每一个迭代里被一个问题一个问题地撞出来,然后被修正进下一版。下面这几个拐点,是我们记得最清楚的。
01 PDCA在迭代7断掉了
PDCA方法论要求每个迭代都走完四步。最初我们以为Agent会自然遵循这个循环——像流水线一样:Plan完了自动Do,Do完了自动Check。
但Agent不是流水线。
迭代7,权限管理。Plan阶段完成了:权限模型设计、角色定义、访问控制规则——逻辑上是通顺的。然后Do、Check、Act三个阶段的标记是 ⏳。
不是"没做"。是Agent在做Do的时候发现Plan里漏了一个关键依赖——前端权限组件还没有实现。它没有能力判断"先实现前端组件"还是"先调整Plan的优先级",也没有能力主动发起一次重新规划。它停在了Do的中间,不知道下一步该怎么走。
V1.0的PDCA假设的是"Plan正确,执行自然顺畅"。但它没有给Agent一个"Plan出错了怎么办"的机制。
CORE FINDING
PDCA不是线性的。每个阶段的失败都是对的——Plan阶段被推翻,意味着Do阶段节省了做无用功的时间。
这是迭代7撞出来的。
02 Service层跳过的测试,在迭代12集中偿还
迭代4和5,FAQ模块和Wiki模块。
Agent的效率确实高——Service层逻辑清晰,SQLAlchemy查询写得比很多中级工程师都好。但有一个选择在当时看起来是合理的:Service层没写测试。
为什么?因为当时的默认逻辑是——Service层调用Repository层,Repository层有测试,所以Service层的业务逻辑被"间接覆盖"了。Agent自己在总结里写的是"Service层逻辑通过Repository层测试间接验证"。
“这话在理论上成立。在实践上,它没有成立。”
迭代12,系统优化阶段。我们决定集中把测试覆盖率从66%拉到81%。结果发现:
FAQ的 Service 层——3个方法边界条件下出错(分页参数为0、空查询字符串)
Wiki的 Service 层——事务提交逻辑bug,mock测试根本不会触发
需要补测 8 个测试文件
这8个文件的补测,是迭代4和5欠的债,利息是迭代12的额外工作量。
V2.0铁律:TDD覆盖的粒度必须是方法级,不是模块级。"间接覆盖"四个字在以后的方法论表述中不再出现。
03 基础设施代码的测试盲区
迭代12做覆盖率提升的时候,我们还发现了另一个问题。
迭代12之前 · 基础设施代码覆盖率为0%
cache.py · minio_client.py · redis_client.py
说实话,不是没人想到要测。但每个人在想"测试"的时候,第一反应永远是"测业务逻辑"。基础设施代码默认被归类为"不需要测"。
但当缓存策略配置错了、Redis连接池没配置好、MinIO的签名URL过期时间不对——这些"没什么逻辑"的代码一样能让系统跑着跑着就挂了。
V2.0在TDD章节里补了一个子模块:基础设施层也需要测试。缓存配置、客户端初始化、连接管理——不复杂,但出错后果不低。
04 部署不是"最后一步",是一整套麻烦
迭代13,6个服务部署:PostgreSQL、Redis、MinIO、Backend、Frontend、Nginx。
听起来不难?结果撞了8个Bug。
有一个特别典型:Alembic迁移脚本执行失败,报ImportError。排查了半天发现——database.py 里没有定义 Base 类。Agent在写迁移脚本的时候,默认"Base 类已经在上下文中了",但实际上它没有把 Base 类定义写进迁移相关的模块。
还有一个更隐蔽的:容器名字和nginx upstream 里配置的不一致。Agent 生成docker-compose.yml的时候用了自定义容器名,但在nginx.conf里用的又是服务名。两个名字不一样,nginx直接502。
V1.0完全没有部署相关的章节。不是忘了。是没料到部署环节会有这么多需要Agent自己判断的上下文细节。
V2.0补了:
Docker Compose配置规范 · 端口管理 · 容器命名与nginx upstream一致性检查
7步部署前检查清单 · 问题诊断流程
部署后自动跑 8项验证 ← 从这8个Bug转化而来
05 AGENT.MD是活的,不是一次性文件
AGENT.MD 在我们的设想里是"顶层规范文件"——定义分层架构、技术栈、质量标准、开发流程。Agent 在开始任何工作之前先读它。
但真正跑起来才发现——它不是一份"写好了就放在那里"的文件。
14个迭代里,它被更新了5次:
迭代 1
初始版本。四层架构、技术栈、质量标准。
迭代 2
补了ES集成规范。Agent用了默认英文分词器,中文搜索结果一塌糊涂。
迭代 12
补了Redis缓存策略。缓存命中率下降跑了一段时间才暴露。
迭代 13
补了部署规范。见拐点四。
迭代 14
补了权限规范。新权限模型和最初设计完全不同,必须同步更新。
没有一次是"按计划更新"的。每一次都是——发生了点什么,不改不行。
V2.0强化了AGENT.MD的演进机制:每次迭代Act阶段强制评估——本迭代是否产生了需要写入AGENT.MD的规范变更?不检查就不能进入下一个迭代的Plan。
▼ ▼ ▼
◆ 最终的变化
一张表就够了
7个维度。从一个理论到一套被证实的系统。
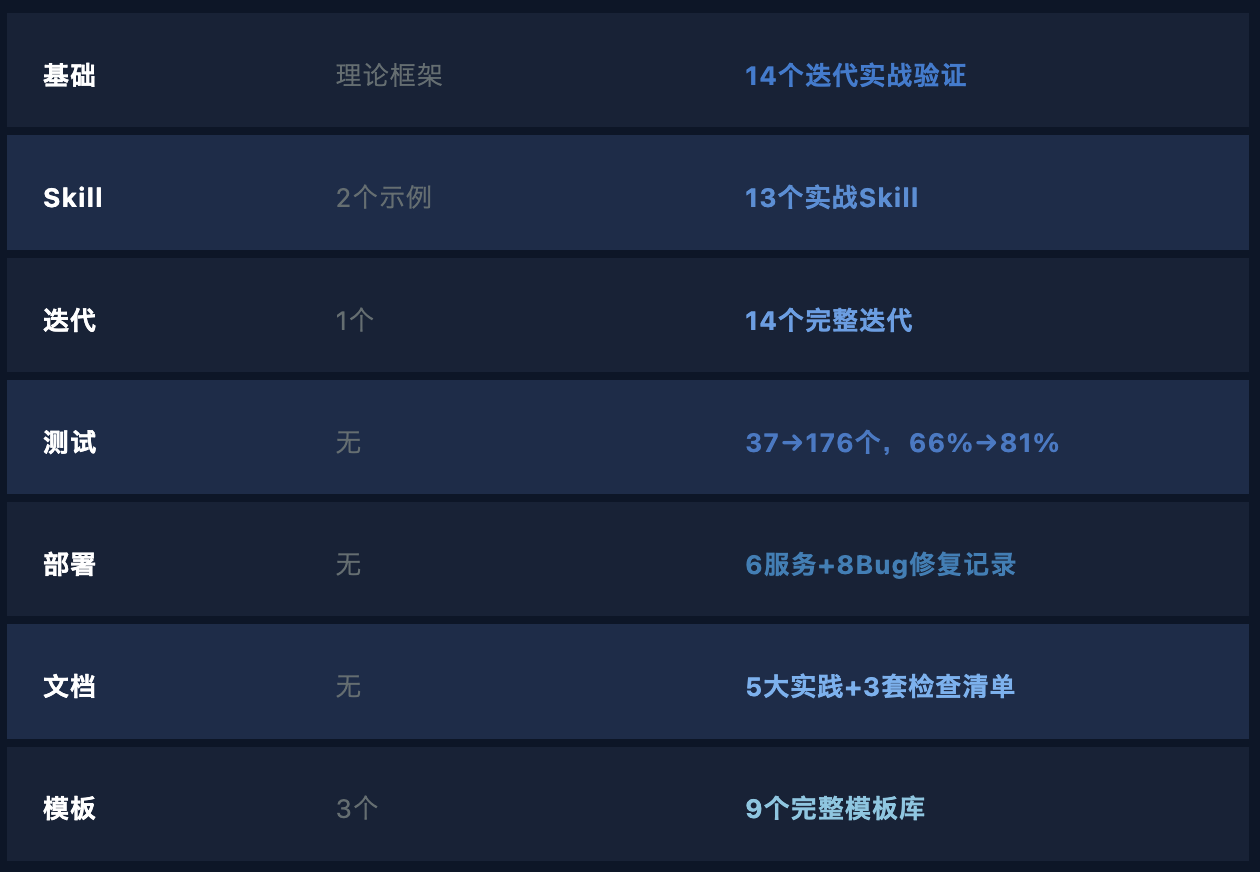
这不是"V2.0比V1.0更好"——这是在说:V1.0里几乎所有东西都被改写了。
不是因为我们一开始想得不周到。没法周到——方法论在纸上,永远遇不到这些东西:具体的人、具体的代码、具体的部署环境、具体的错误信息。
▼ ▼ ▼
方法论不是天上掉下来的
我们经常看到一些文章说"我们总结了一套方法论",然后列出一堆漂亮的框架图和原则。
但我们自己的经历恰好相反。
方法论不是总结出来的。是撞了墙之后,在复盘记录里翻出来,再塞进下一版。
PDCA断了一次 → 知道Plan的价值不在"写完了",而在"Do能执行得下去"
Service测试跳了一次 → 知道"间接覆盖"四个字应该被禁用
部署撞了8个Bug → 下次就有了一整套自动化验证清单
14个迭代,14次"我以为没问题",14次"啧,这不对"
V1.0到V2.0的进化,就是在这些微小的、具体的、不完美的时刻里发生的。没有一蹴而就,只有撞了再改、改了再撞、撞到终于不那么容易撞了。
“下一版还会改。这是确定的事情。”
织灵 Coda Loom · 实战手记
让研发工程回归创造