



基于企业知识库系统 14 个迭代的ADE 软件开发优秀实践总结。
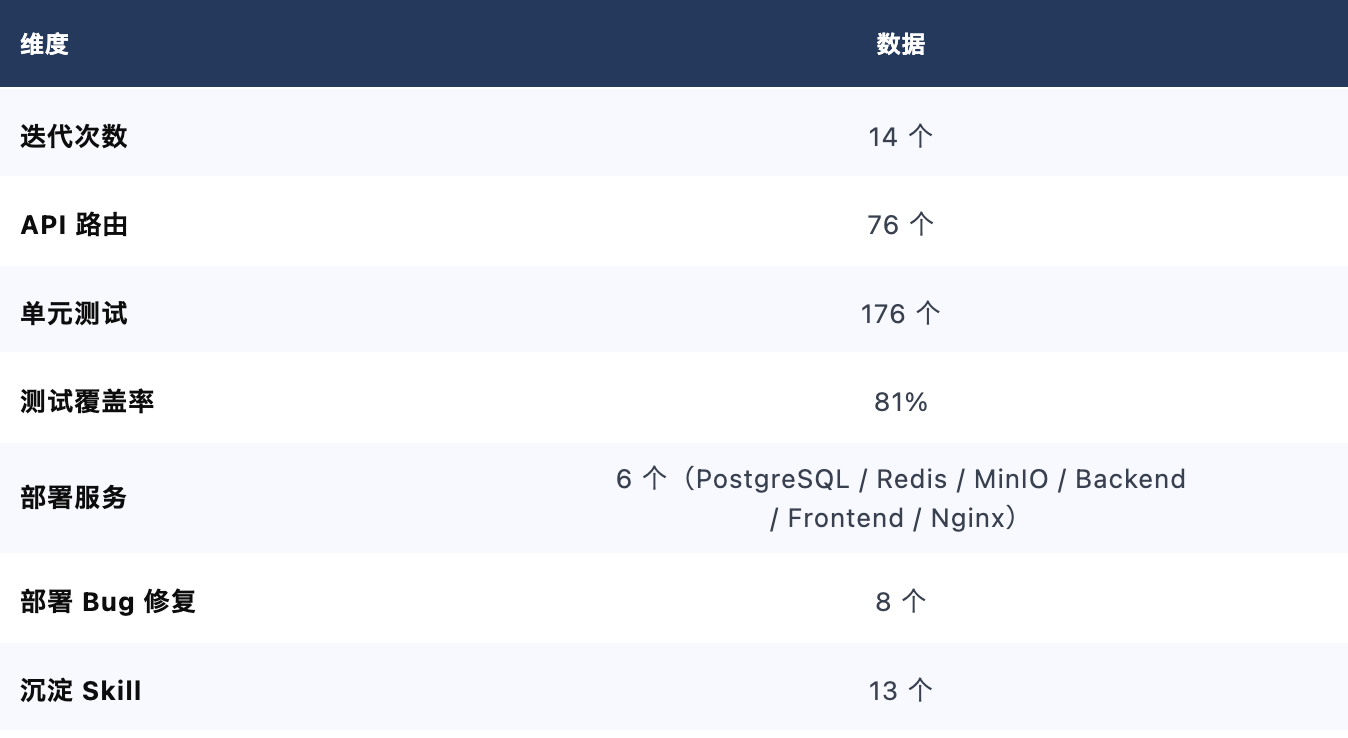
项目成果:76 个 API 路由 · 176 个单元测试 · 81% 测试覆盖率 · 6 服务一键部署
◆ KEY INSIGHT
AI 写代码很快,但写完就忘。每开一个新会话,Agent 从零开始——上下文归零、架构决策丢失、踩过的坑白踩。这不是工具的错。是方法论的缺失。
我们用一个真实项目——企业知识库系统
14 个迭代,76 个 API 路由,176 个单元测试,81% 覆盖率——完整验证了一套工程方法论:SDD + Skill + TDD + PDCA + 执行状态管理。
结果不是「AI 能写代码了」,而是 「AI 能在工程级项目中持续交付高质量代码」。
本文是完整实践总结。不聊理念,聊怎么做。
本文档总结了 ADE(AI Development & Research Engineer)在开发企业知识库系统过程中沉淀的优秀实践。项目历时 14 个迭代,从需求分析到部署上线,覆盖基础设施搭建、核心功能开发、系统优化、远程部署等完整软件生命周期。
项目概览
技术栈
后端:Python + FastAPI + SQLAlchemy + Alembic
前端:React + TypeScript
数据库:PostgreSQL + Redis + Elasticsearch + MinIO
部署:Docker Compose + Nginx
测试:pytest + pytest-asyncio
规范:ruff
● ● ●
CHAPTER 01 | 实践一:PDCA 驱动的迭代开发
对应方法论第一章:PDCA驱动的整体架构
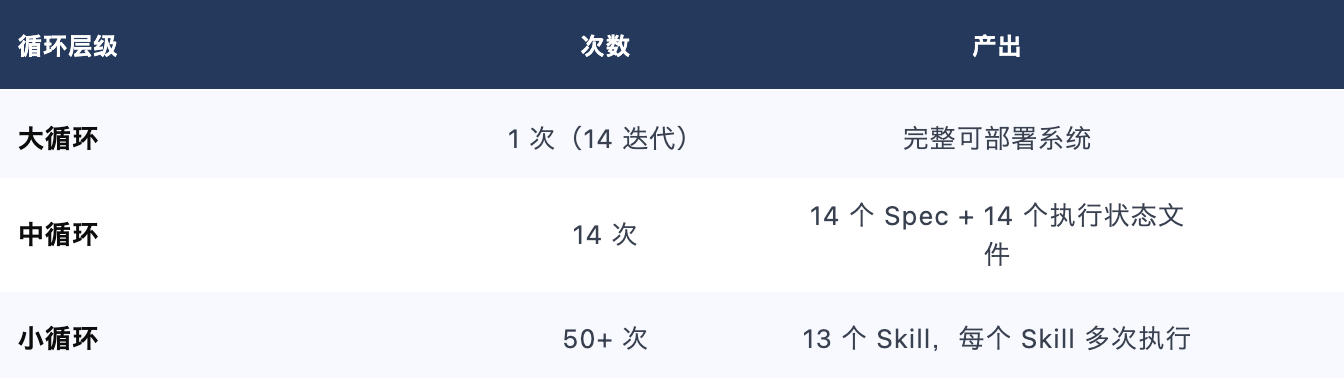
1.1 三层 PDCA 循环实战
代码块
大循环(项目级): 14 个迭代,从需求分析到部署上线
↓
中循环(Spec级): 每个迭代独立 PDCA,14 个完整闭环
↓
小循环(Skill级): 每个 Skill 执行独立 PDCA,累计 50+ 次
实战数据:
1.2 PDCA 各阶段实践
Plan(规划)— 迭代前必须完成
-
编写 Spec 文档,明确目标、范围、验收标准
-
引用所需 Skill,不临时定义能力
-
创建执行状态文件,初始状态为 Plan ⏳
Do(执行)— 按 Skill 步骤推进
-
读取 Spec → 加载 Skill → 按步骤执行
-
功能级 TDD:Red → Green → Refactor
-
每完成一个功能,更新执行状态
Check(验证)— 量化验证
-
运行全部测试,统计通过率
-
检查测试覆盖率(目标 ≥ 80%)
-
代码审查(ruff 检查)
Act(改进)— 经验沉淀
-
复盘:做得好的 / 需要改进的
-
优化 Skill:根据执行反馈更新
-
更新规范:将经验沉淀到 AGENT.MD
-
固化状态:更新执行状态文件
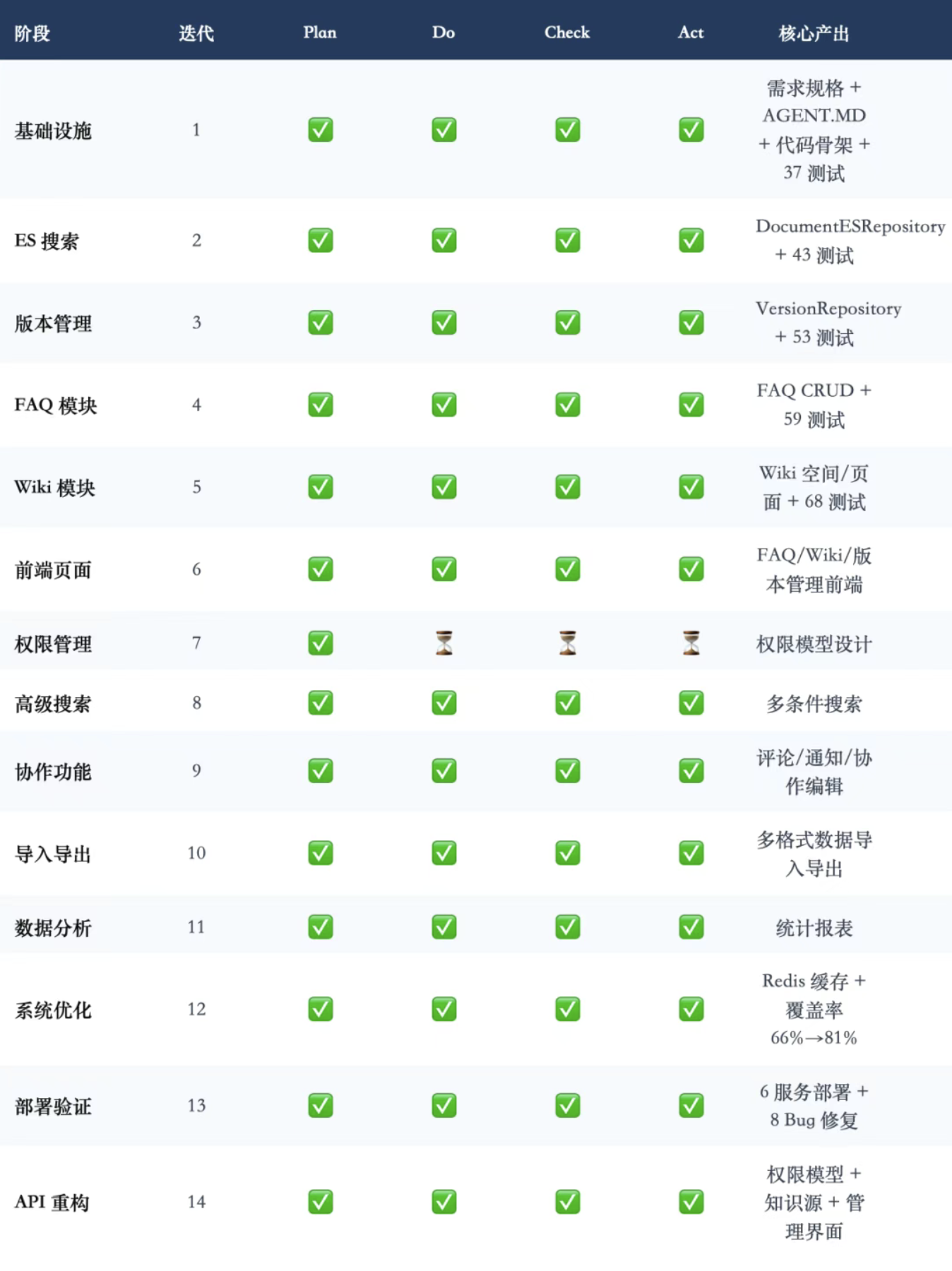
1.3 14 个迭代 PDCA 执行效果
● ● ●
CHAPTER 02 | 实践二:AGENT.MD 规范管控
对应方法论第二章:AGENT.MD 规范管控
2.1 AGENT.MD 实战作用
AGENT.MD 作为顶层管控文件,在 14 个迭代中持续发挥作用:
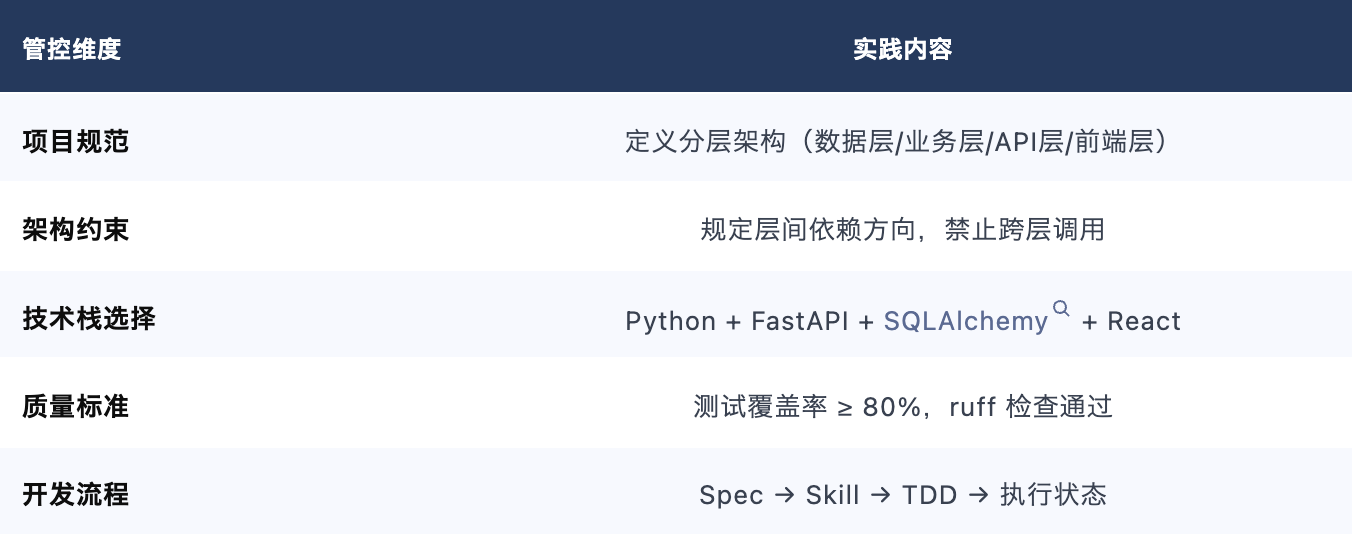
2.2 规范演进记录
AGENT.MD 在 Act 阶段持续更新,主要演进:
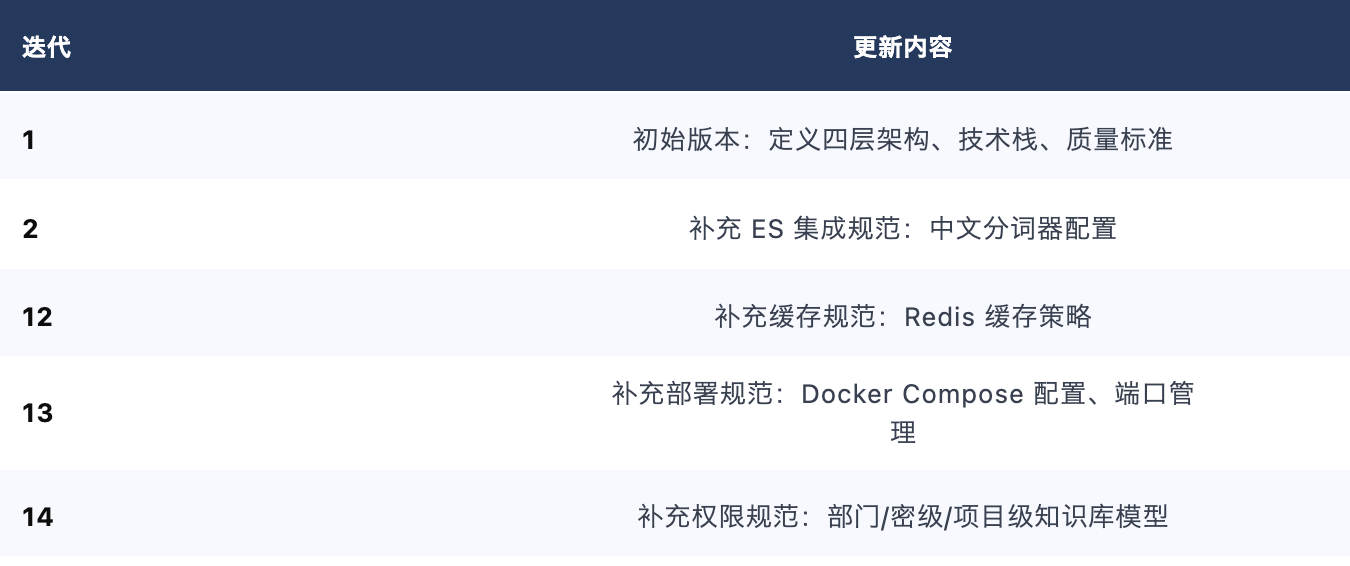
2.3 管控原则落地
强制性:所有开发活动遵循 AGENT.MD 定义
-
每个 Spec 必须引用 AGENT.MD 中定义的 Skill
-
代码分层严格遵循架构约束
可追溯:每个决策有文档记录
-
技术决策记录在执行状态文件中
-
14 个迭代累计记录 20+ 个技术决策
可演进:规范随项目演进更新
-
每次迭代 Act 阶段评估是否需要更新 AGENT.MD
-
新增 Skill 时同步更新 Skill 清单
● ● ●
CHAPTER 03 | 实践三:Skill 驱动开发
对应方法论第三章:Skill驱动开发
3.1 Skill 体系实战
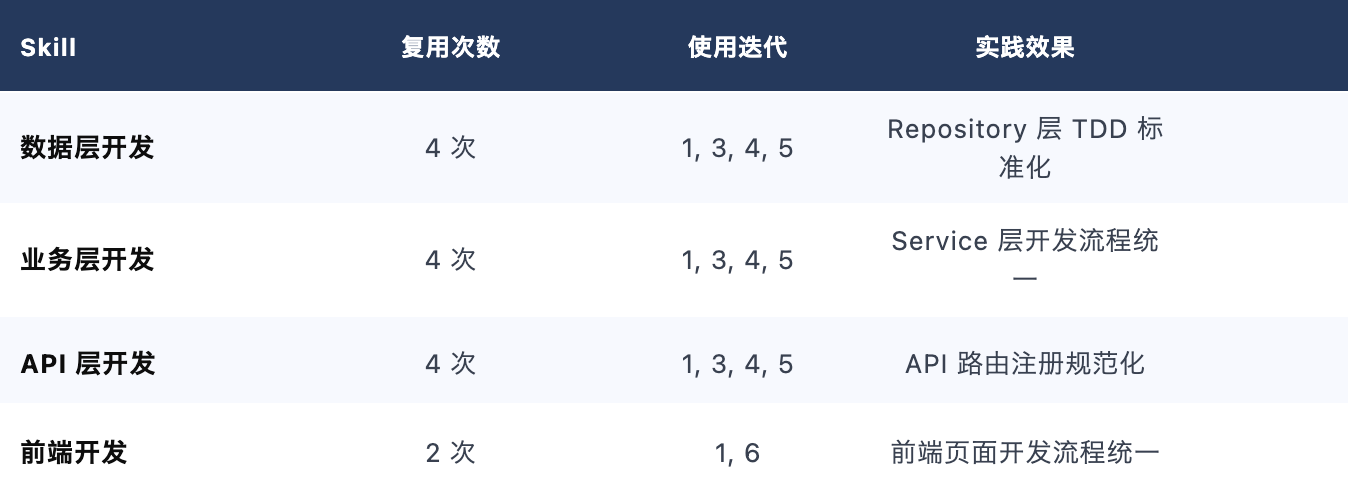
经过 14 个迭代沉淀,形成 13 个 Skill:
层面 Skill(高度复用)
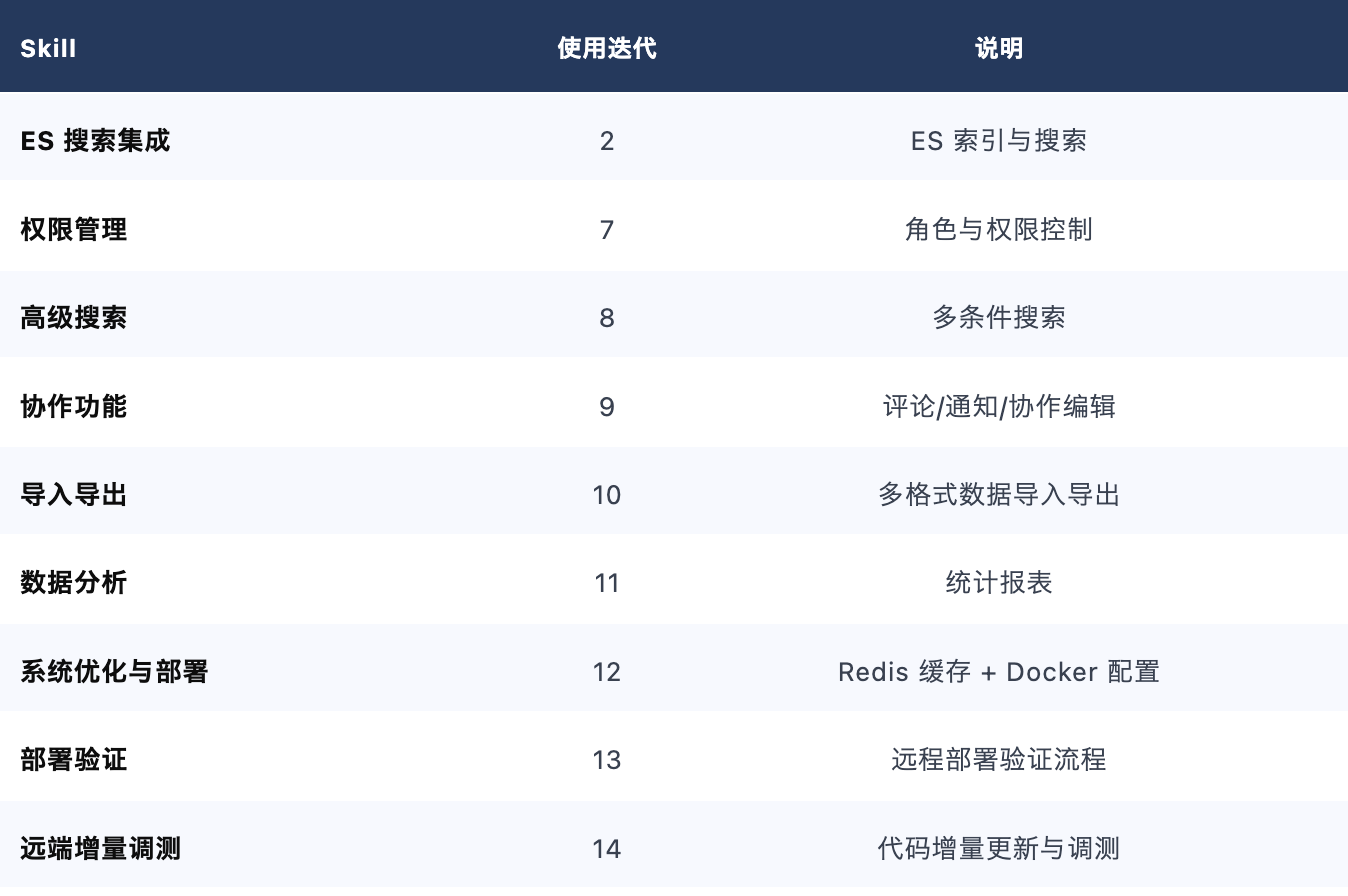
功能 Skill(按需创建)
3.2 Skill 创建时机
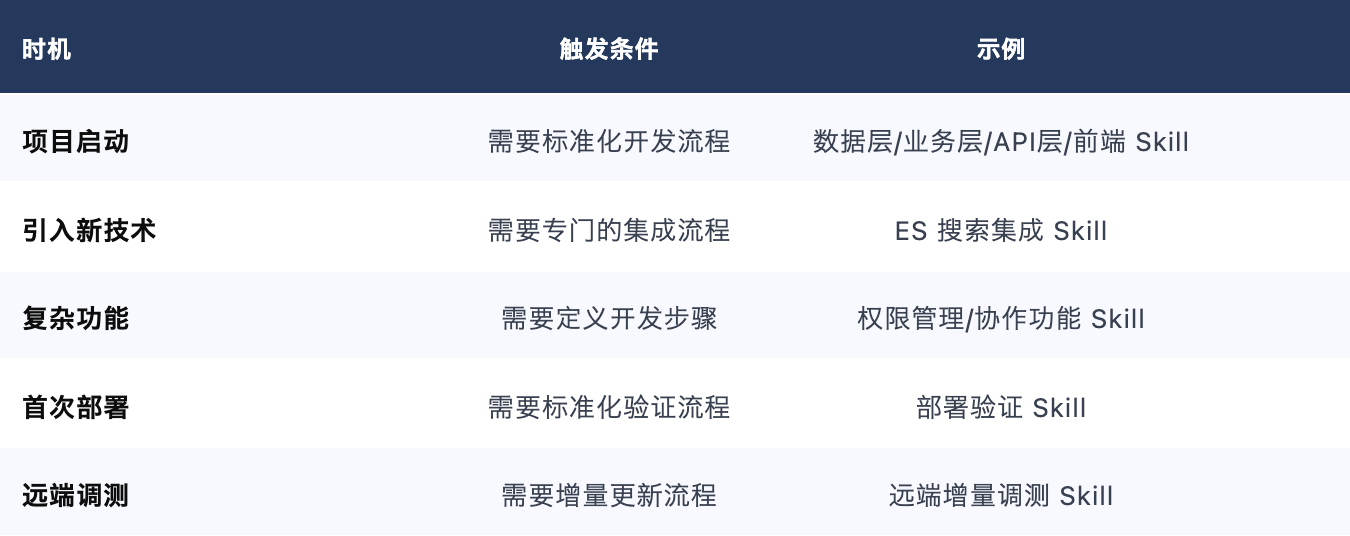
3.3 Skill 维护原则
-
层面 Skill 保持稳定 — 数据层/业务层/API 层 Skill 在 4 个迭代中复用,核心步骤不变
-
功能 Skill 使用后优化 — 每次执行后根据反馈更新步骤
-
部署类 Skill 补充问题处理 — 部署验证 Skill 在迭代 13 执行后补充 8 个 Bug 处理方案
-
经验教训沉淀 — 每个 Skill 的“注意事项”部分持续更新
3.4 TDD 分层 Mock 策略
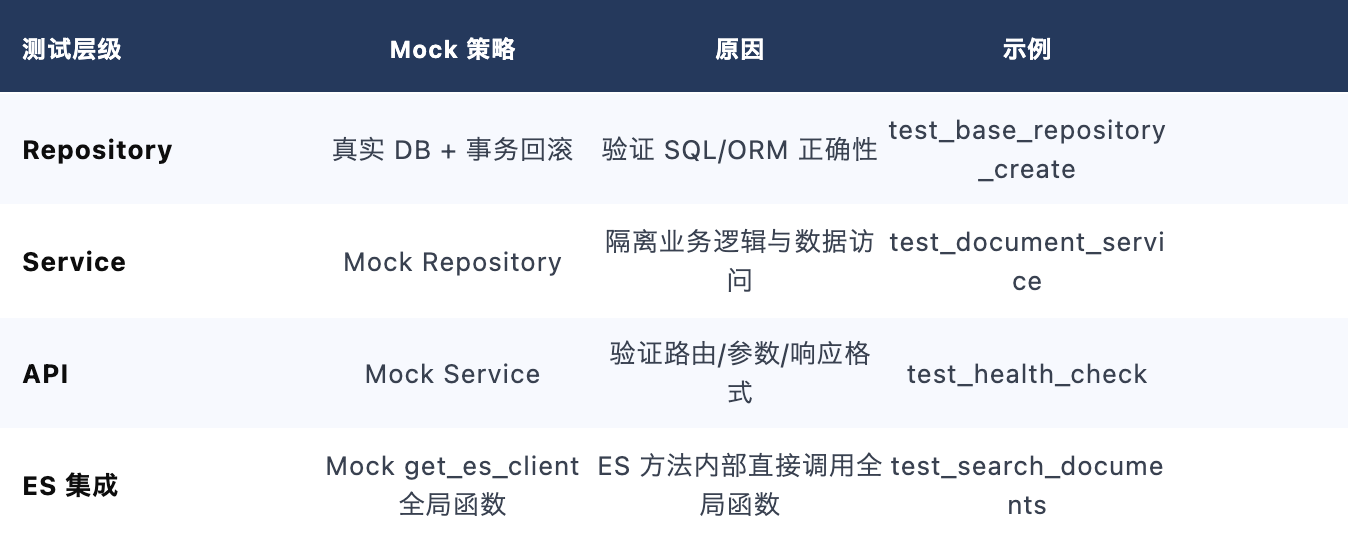
⚠️ 常见陷阱:
Python
# 陷阱 1:MagicMock 的 name 参数是内部保留字mock_obj = MagicMock(name="service") # ❌
# 正确:逐行赋值mock_obj = MagicMock()mock_obj.name = "service" # ✅
# 陷阱 2:ES 集成 Mock 了错误的对象@patch("src.services.DocumentESRepository") # ❌
# 正确:Mock 全局函数@patch("src.utils.es_client.get_es_client") # ✅
3.5 覆盖率提升路径
通过迭代 12 的 Act 阶段集中补测,覆盖率从 66% 提升到 81%:
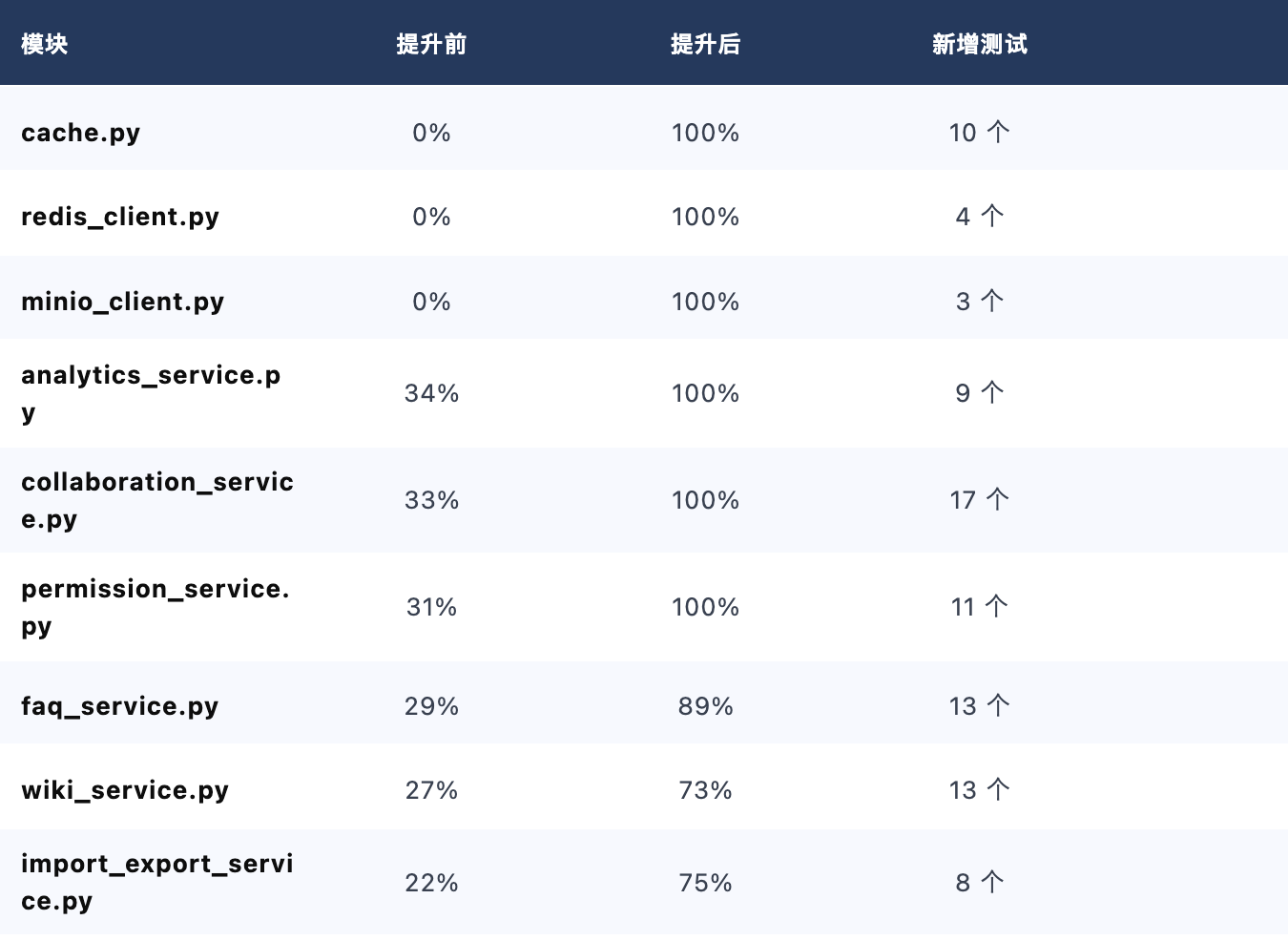
⚠️ 关键教训:Service 层不能跳过测试 — 迭代 4、5 的 Service 层未写测试,导致迭代 12 需要集中补测 8 个测试文件。
● ● ●
CHAPTER 04 | 实践四:迭代分解驱动
对应方法论第四章:迭代分解驱动
4.1 分解原则实战
代码块
项目 → 阶段 → 层面 → 功能 → 模块 → 组件 → 函数
14 个迭代分解路径:

4.2 每层分解遵循的规则
-
先定义 Skill — 明确该层级的能力需求
-
再开展活动 — 使用 Skill 执行开发
-
过程文档化 — 记录决策和实现细节
-
TDD 原子实现 — 最底层用 TDD 完成
4.3 前后端协同实践

⚠️ 教训:前端需要测试体系 — 整个开发过程前端无单元测试,质量依赖手动验证。
4.4 数据模型与迁移管理
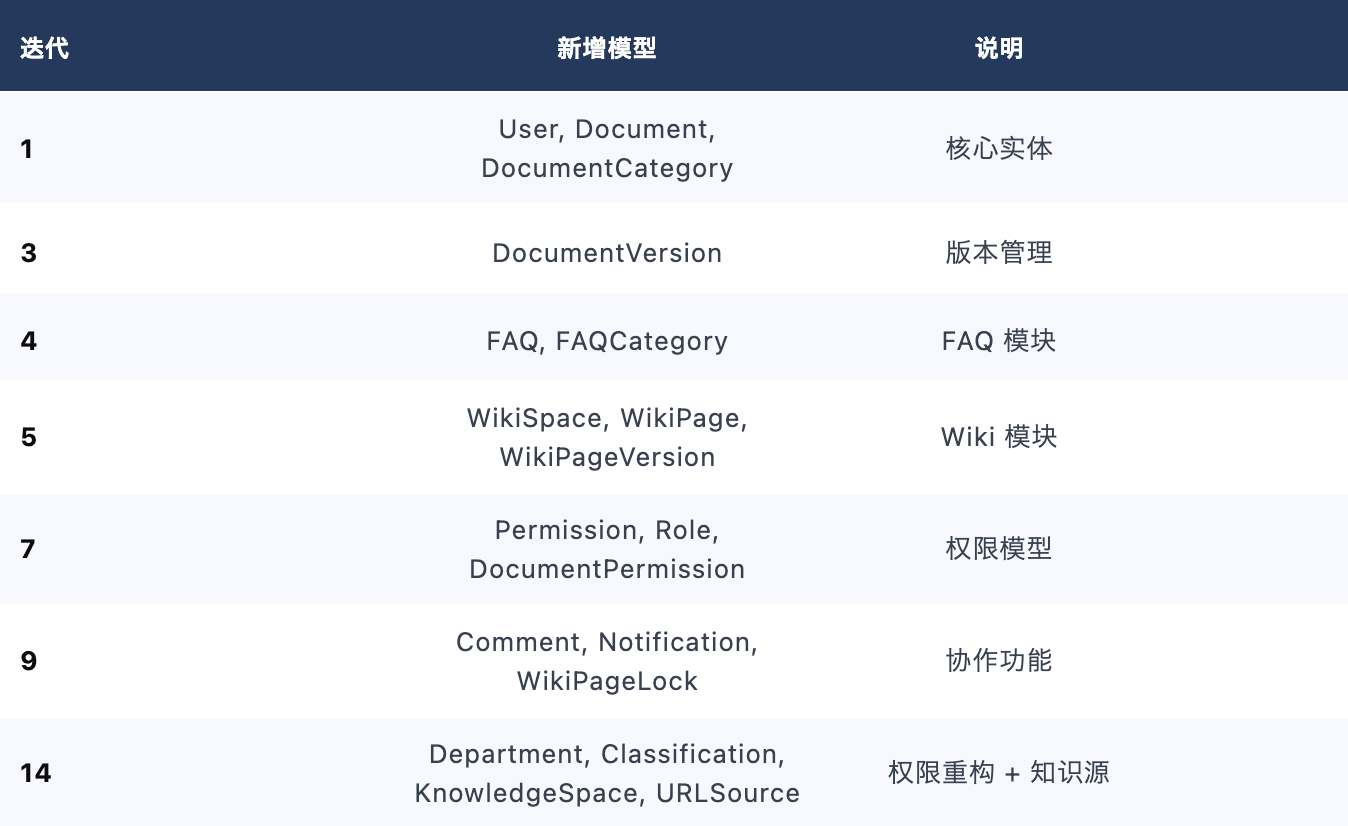
⚠️ 迁移最佳实践:
Bash
# 1. 生成迁移脚本alembic revision --autogenerate -m "add_department_classification"
# 2. 迁移前验证模型导入python -c "from src.models import Base; print('OK')"
# 3. 执行迁移alembic upgrade head
4.5 远程部署与问题排查
部署检查清单:
代码块
□ Docker / Compose 版本确认
□ 端口占用检查(含 iptables REDIRECT 规则)
□ 宿主机服务冲突检查(nginx / uvicorn 等)
□ 容器命名与 nginx upstream 一致性
□ 环境变量配置完整性
□ 数据库迁移脚本验证
□ 磁盘空间与内存检查
迭代 13 部署 8 个 Bug 修复:
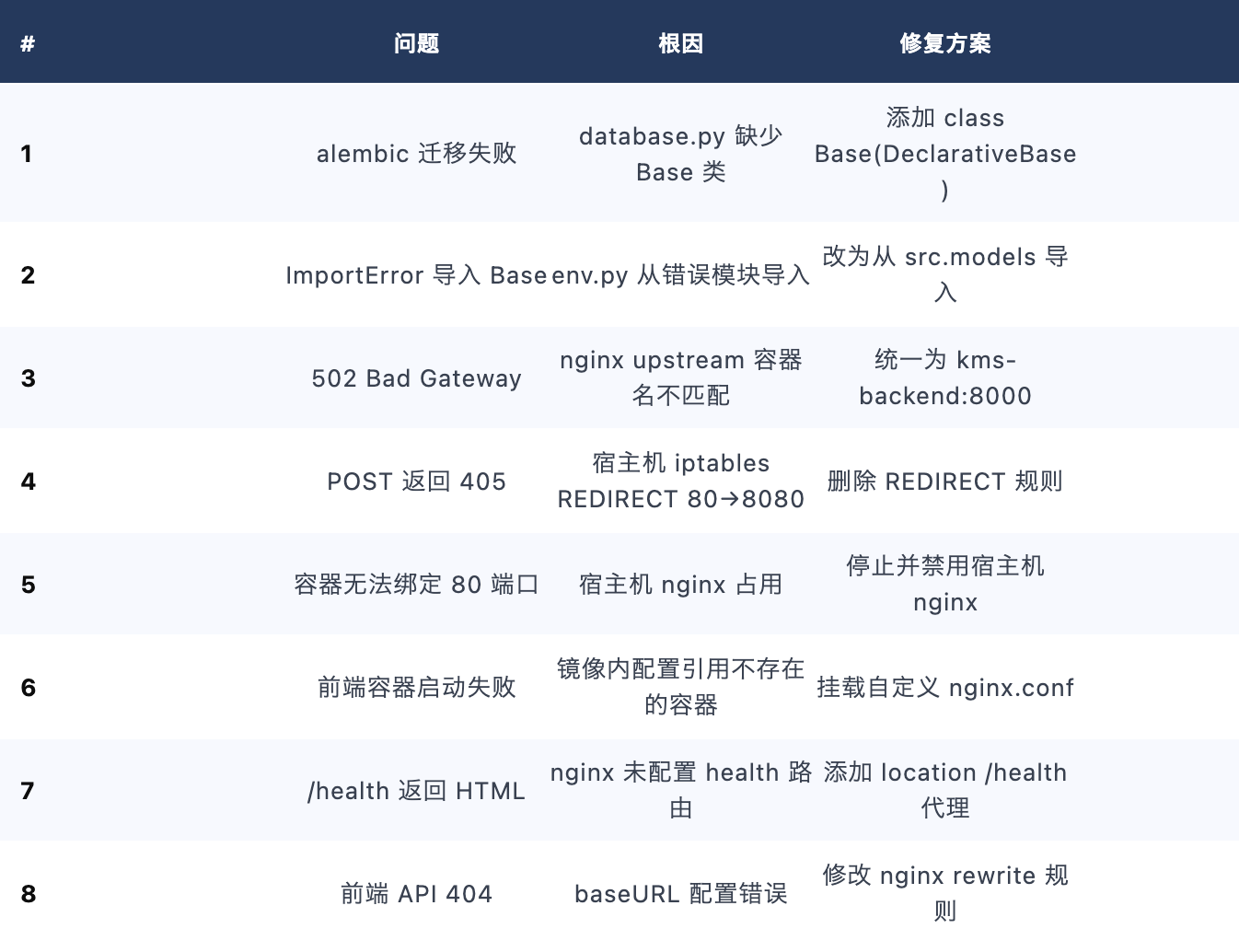
问题诊断流程:
代码块
1. 查看日志 → docker logs <container>
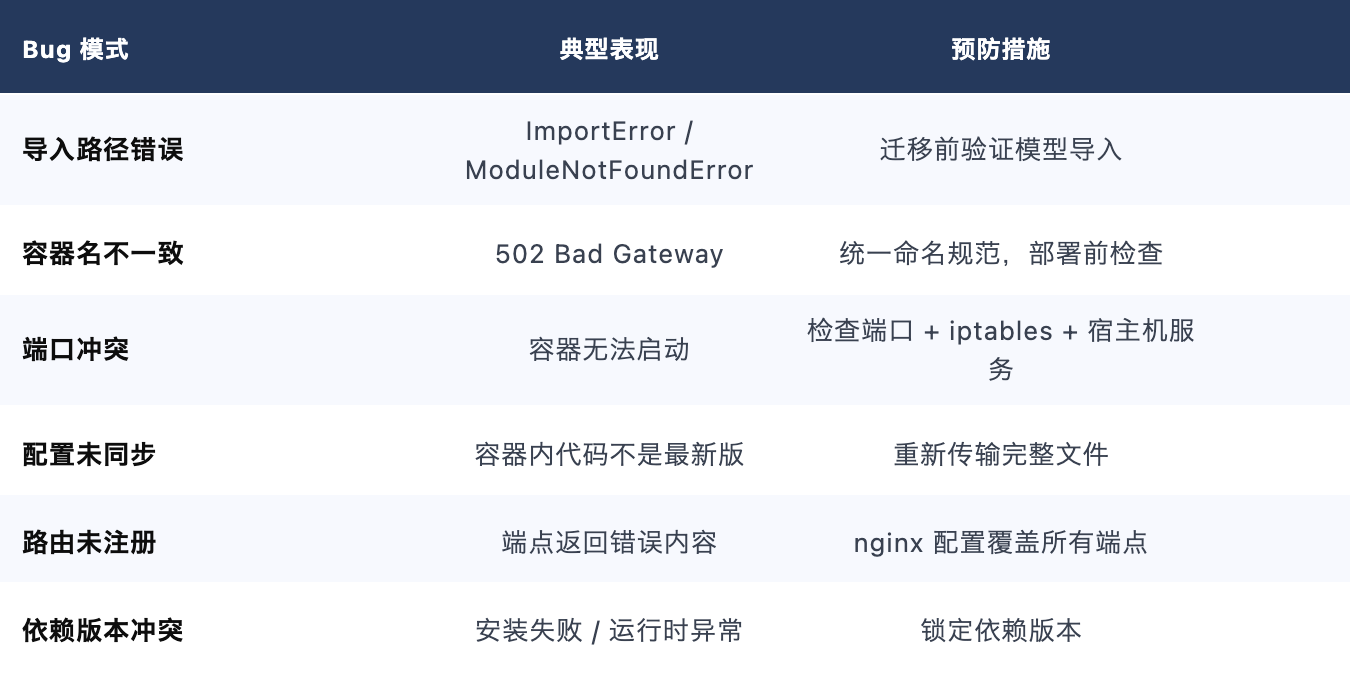
4.6 常见 Bug 模式与预防
● ● ●
CHAPTER 05 | 实践五:执行状态追踪
对应方法论第五章:执行状态追踪
5.1 文档体系实战

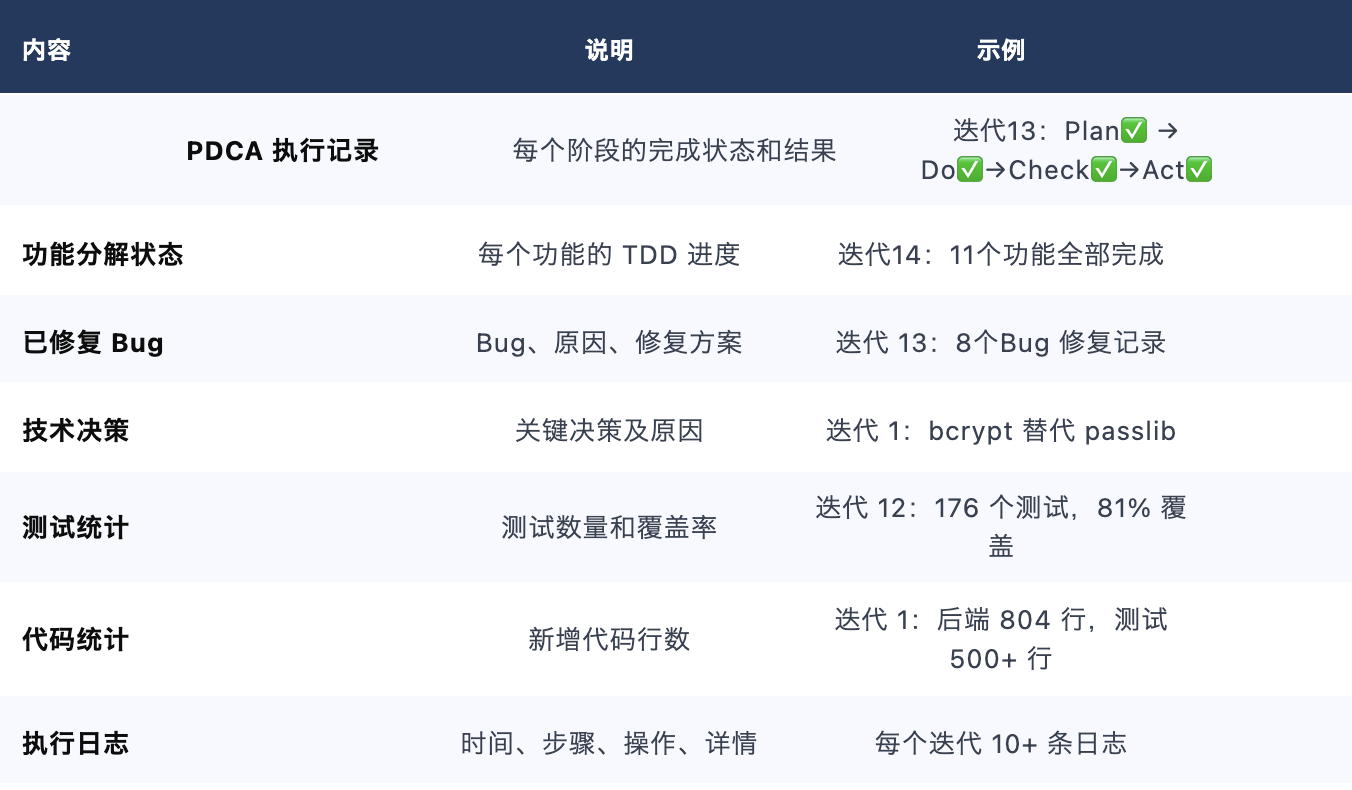
5.2 执行状态文件价值
14 个迭代的执行状态文件记录了完整的开发过程:
5.3 Spec 与执行状态分离的优势
Spec 文件不修改 — 保持迭代计划的稳定性
执行状态文件动态更新 — 实时反映开发进展
代码块
迭代 13 执行状态演进:
Plan ⏳ → Plan ✅ (环境检查完成)
→ Do ⏳ → Do ✅ (6 服务部署成功)
→ Check ⏳ → Check ✅ (全部验证通过)
→ Act ⏳ → Act ✅ (8 个 Bug 修复)
5.4 代码规范与质量
ruff 检查结果:
Bash
ruff check --fix .
# 44 个 import 排序问题 → 自动修复 ✅
# 47 个 E501 行超长 → 历史问题,后续处理
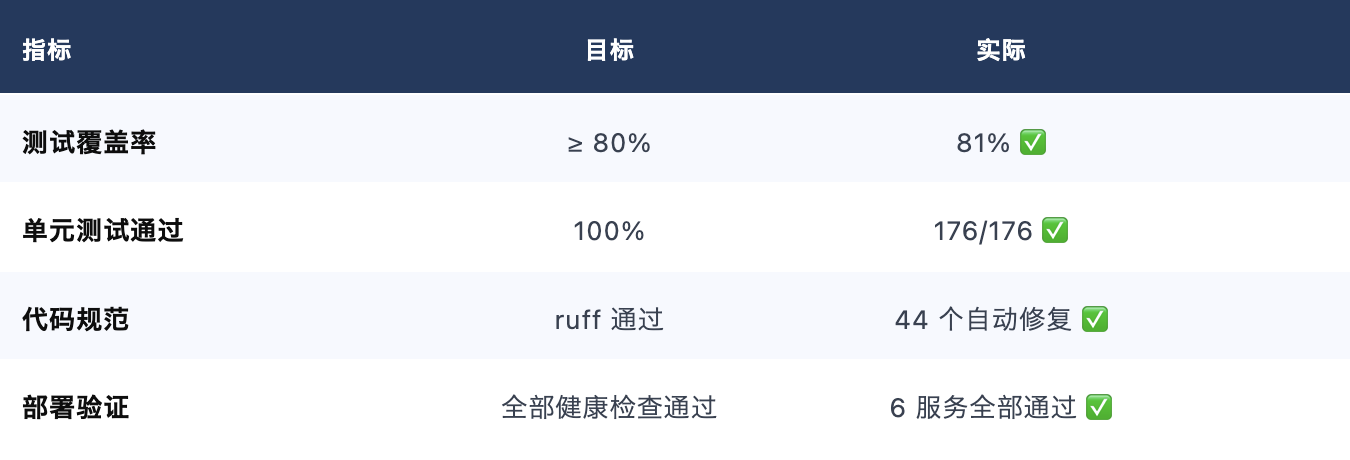
质量指标达成:
总结
通过 14 个迭代的实战,ADE 方法论从理论框架演进为经过验证的工程实践:
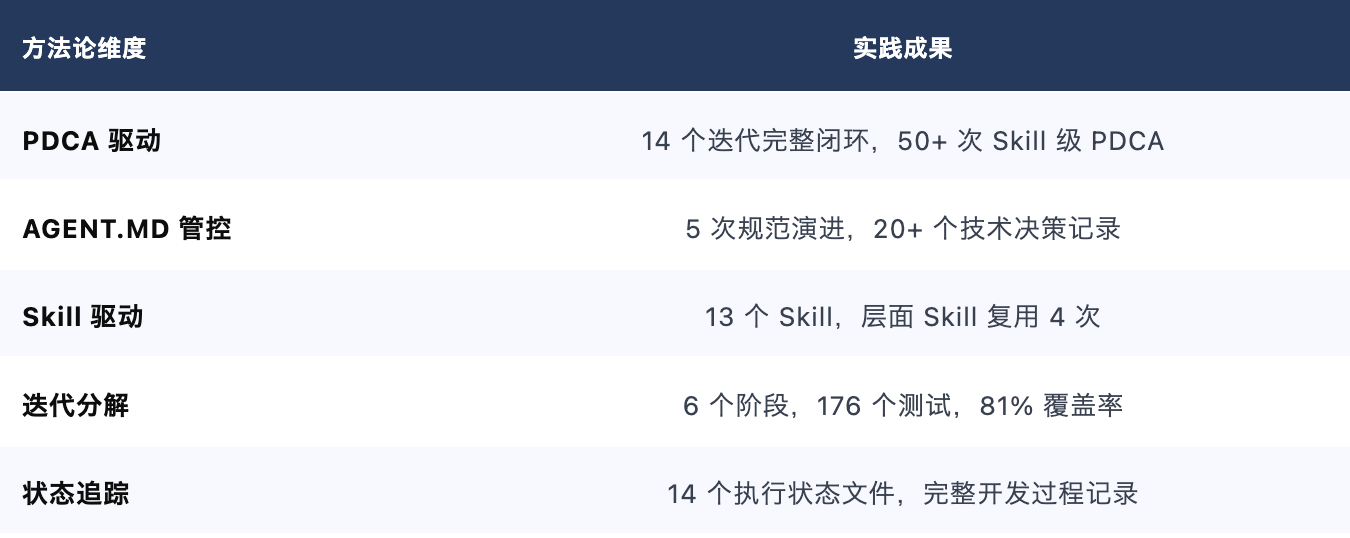
这些实践可直接应用于后续项目的开发,减少重复踩坑,提高交付质量。
V1.0 → V2.0 变更
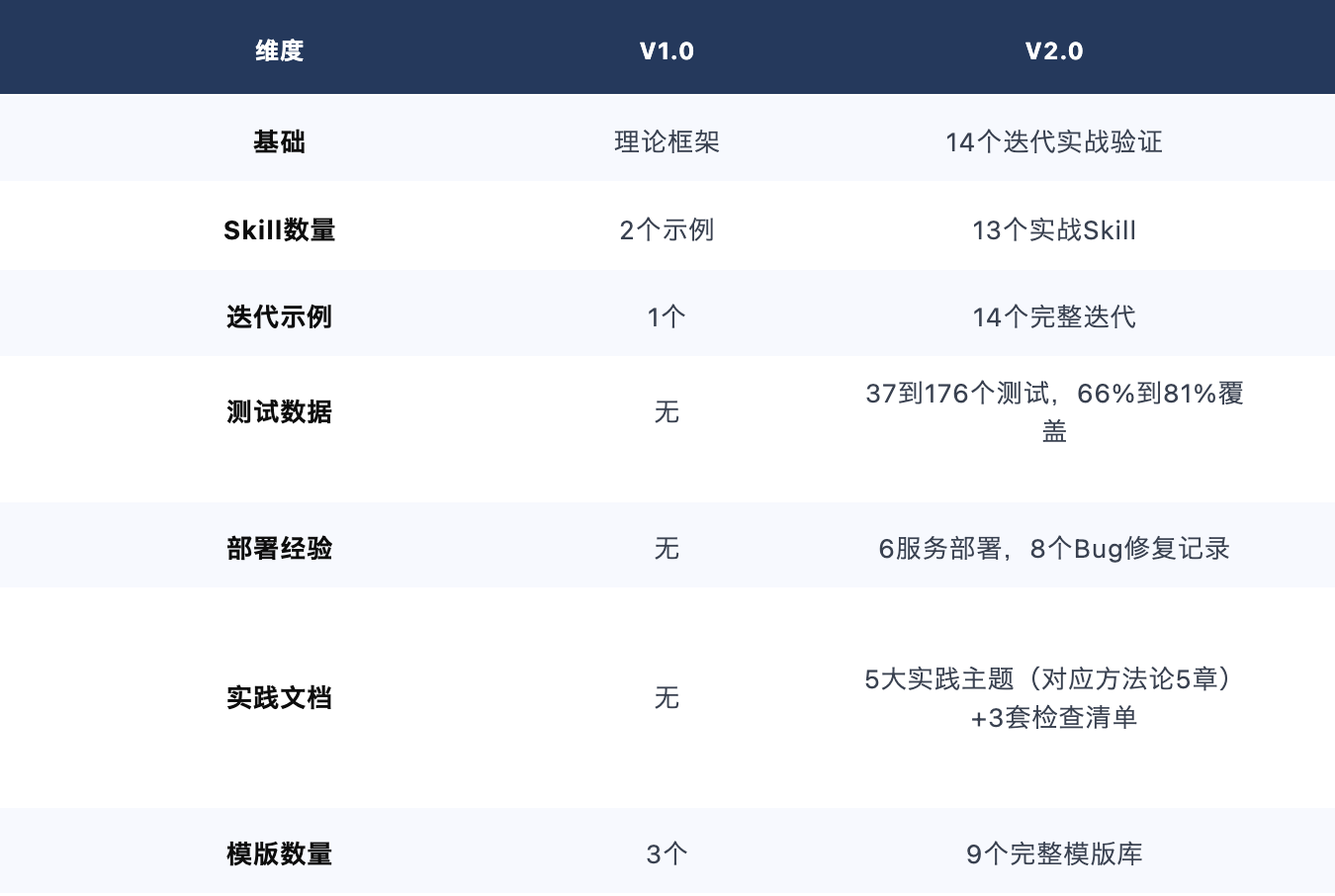
● ● ●
写在最后:方法论才是分水岭
14个迭代 · 50+次PDCA小循环 · 13个Skill · 176个测试 · 81%覆盖率 · 6服务一键部署
◆ CORE FINDING
AI编程的下一个分水岭,不是模型能力,是工程方法。
模型会越来越强。但如果没有PDCA的闭环、没有Skill的知识沉淀、没有执行状态的全程追踪,模型再强也只是「单次高效、跨会话归零」。
真正的工程级AI开发,需要的是:
——执行状态追踪
——Skill体系
——AGENT.MD管控
——PDCA驱动
"AI不会替代工程师。
会用AI的工程师,会替代不会用的。”
——但前提是,你得有一套让AI可管理、可追溯、可进化的工程方法。